Are you looking for an answer to the topic “unicodedecodeerror“? We answer all your questions at the website Chambazone.com in category: Blog sharing the story of making money online. You will find the answer right below.
Keep Reading

How do I fix UnicodeDecodeError in Python?
- Introduction. Encoding and Decoding.
- #Fix 1: Set an Encoding Parameter.
- #Fix 2: Change The Encoding of The File.
- #Fix 3: Identify the encoding of the file.
- #Fix 4: Use engine=’python’
- #Fix 5: Use encoding= latin1 or unicode_escape.
- Conclusion.
What does UnicodeDecodeError mean?
The UnicodeDecodeError normally happens when decoding an str string from a certain coding. Since codings map only a limited number of str strings to unicode characters, an illegal sequence of str characters will cause the coding-specific decode() to fail.
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte
Images related to the topicUnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte
What is UTF-8 codec can’t decode byte?
If you are getting UnicodeDecodeError while reading and parsing JSON file content, it means you are trying to parse the JSON file, which is not in UTF-8 format. Most likely, it might be encoded in ISO-8859-1. Hence try the following encoding while loading the JSON file, which should resolve the issue.
Is UTF-8 and ASCII same?
For characters represented by the 7-bit ASCII character codes, the UTF-8 representation is exactly equivalent to ASCII, allowing transparent round trip migration. Other Unicode characters are represented in UTF-8 by sequences of up to 6 bytes, though most Western European characters require only 2 bytes3.
How do I check the encoding of a CSV file?
The evaluated encoding of the open file will display on the bottom bar, far right side. The encodings supported can be seen by going to Settings -> Preferences -> New Document/Default Directory and looking in the drop down.
What is Unicode_escape?
The encoding `unicode_escape` is not about escaping unicode characters. It’s about python source code. It’s defined as: > Encoding suitable as the contents of a Unicode literal in ASCII-encoded Python source code, except that quotes are not escaped.
What is 0xC3?
0xC3 it’s a metadata byte that means that the character it’s encoded with 1 byte, 0xA9, but the unicode value for é is 0xE9.
See some more details on the topic unicodedecodeerror here:
UnicodeDecodeError – Python Wiki
The UnicodeDecodeError normally happens when decoding an str string from a certain coding. Since codings map only a limited number of str …
‘utf8’ codec can’t decode byte 0xa5 in position 0: invalid start …
The UnicodeDecodeError normally happens when decoding a string from a certain coding. Since codings map only a limited number of str strings to …
How to resolve a UnicodeDecodeError for a CSV file | Kaggle
_string_box_utf8() UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xcc in position 1: invalid continuation byte During handling of the above exception, …
‘charmap’ codec can’t decode byte 0x81 in position X … – GitHub
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x81 in position X: character maps to
What is the difference between UTF-8 and ISO 8859 1?
UTF-8 is a multibyte encoding that can represent any Unicode character. ISO 8859-1 is a single-byte encoding that can represent the first 256 Unicode characters. Both encode ASCII exactly the same way.
What is utf8 in Python?
UTF-8 is one of the most commonly used encodings, and Python often defaults to using it. UTF stands for “Unicode Transformation Format”, and the ‘8’ means that 8-bit values are used in the encoding.
How do I know the encoding of a text file?
Open the file with Notepad++ and will see on the right down corner the encoding table name. And in the menu encoding you can change the encoding table and save the file.
Is a UTF 8 character?
UTF-8 (UCS Transformation Format 8) is the World Wide Web’s most common character encoding. Each character is represented by one to four bytes. UTF-8 is backward-compatible with ASCII and can represent any standard Unicode character.
Importing CSV or Text or Flat file in Python using Pandas| Fix UnicodeDecodeError in read_csv
Images related to the topicImporting CSV or Text or Flat file in Python using Pandas| Fix UnicodeDecodeError in read_csv

Why do we get unicode errors?
When we use such a string as a parameter to any function, there is a possibility of the occurrence of an error. Such error is known as Unicode error in Python. We get such an error because any character after the Unicode escape sequence (“ \u ”) produces an error which is a typical error on windows.
What is unicode escape Python?
In Python source code, Unicode literals are written as strings prefixed with the ‘u’ or ‘U’ character: u’abcdefghijk’. Specific code points can be written using the \u escape sequence, which is followed by four hex digits giving the code point. The \U escape sequence is similar, but expects 8 hex digits, not 4.
Why is UTF-8 used?
Why use UTF-8? An HTML page can only be in one encoding. You cannot encode different parts of a document in different encodings. A Unicode-based encoding such as UTF-8 can support many languages and can accommodate pages and forms in any mixture of those languages.
Is it more efficient to use ASCII or UTF-8 as an encoding?
There is absolutely no difference in this case; UTF-8 is identical to ASCII in this character range. If storage is an important consideration, maybe look into compression. A simple Huffman compression will use something like 3 bits per byte for this kind of data.
Is Unicode same as UTF?
The Difference Between Unicode and UTF-8
Unicode is a character set. UTF-8 is encoding. Unicode is a list of characters with unique decimal numbers (code points).
What is the default encoding for CSV?
Exporting to CSV uses a default encoding of Unicode (UTF-16le).
How do I change the encoding of a CSV file?
- Navigate to File > Export To > CSV.
- Under Advanced Options, select Unicode(UTF-8) option for Text Encoding.
- Click Next. Enter the name of the file and click Export to save your file with the UTF-8 encoding.
What is difference between ANSI and UTF-8?
ANSI and UTF-8 are both encoding formats. ANSI is the common one byte format used to encode Latin alphabet; whereas, UTF-8 is a Unicode format of variable length (from 1 to 4 bytes) which can encode all possible characters.
What is Surrogateescape?
[surrogateescape] handles decoding errors by squirreling the data away in a little used part of the Unicode code point space. When encoding, it translates those hidden away values back into the exact original byte sequence that failed to decode correctly.
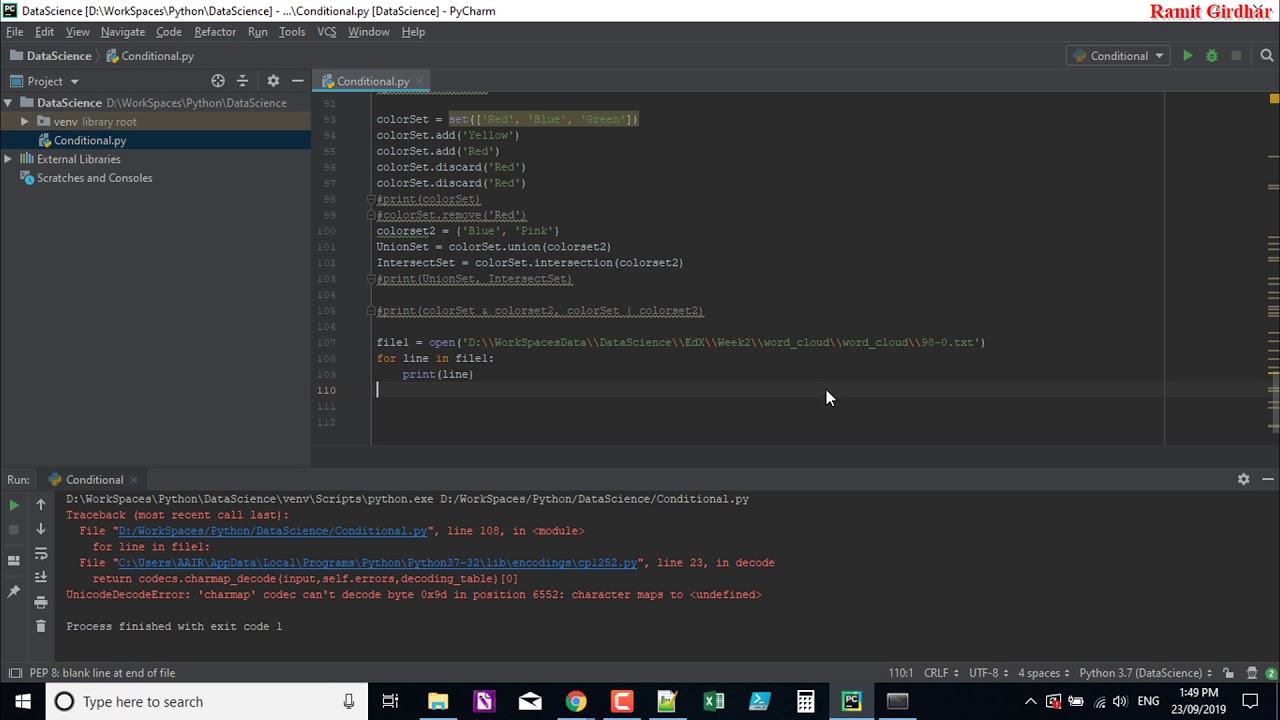
Solved – UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x9d
Images related to the topicSolved – UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x9d
What is Unicode in NLP?
NLP models often handle different languages with different character sets. Unicode is a standard encoding system that is used to represent characters from almost all languages. Every Unicode character is encoded using a unique integer code point between 0 and 0x10FFFF .
What are Python codecs?
The codecs module defines a set of base classes which define the interface and can also be used to easily write your own codecs for use in Python. Each codec has to define four interfaces to make it usable as codec in Python: stateless encoder, stateless decoder, stream reader and stream writer.
Related searches to unicodedecodeerror
- python unicodedecodeerror
- unicodedecodeerror pandas
- unicodedecodeerror in python
- unicodedecodeerror read_csv
- unicodedecodeerror read csv
- zoeken op gsm nummer
- gsm nummer
- unicodedecodeerror python
- unicodedecodeerror utf 8 codec cant decode byte
- unicodedecodeerror: ‘utf-8
- python unicodedecodeerror ‘utf-8’
- unicodedecodeerror charmap
- qué es una democracia
- 080 nummer
- курды и турки отличия
- unicodedecodeerror ‘charmap’ codec can’t decode
- pandas unicodedecodeerror
- unicodedecodeerror ‘utf-8’
- как узнать длину окружности
- unicodedecodeerror in python json
- unicodedecodeerror utf 8
- num_words in tokenizer
- unicodedecodeerror: ‘charmap
- unicodedecodeerror python 3
Information related to the topic unicodedecodeerror
Here are the search results of the thread unicodedecodeerror from Bing. You can read more if you want.
You have just come across an article on the topic unicodedecodeerror. If you found this article useful, please share it. Thank you very much.